Mathématiques 2: Statistiques : Distribution d’échantillonnage
Le but de l'échantillonnage en statistiques est de
déterminer, à partir de paramètres connues sur une population,
ceux d'un échantillon prélevé de cette population.
On distingue deux cas : celui où l'on étudie la moyenne
dans un échantillon et celui où l'on étudie la proportion dans un échantillon.
1. Moyenne d'un échantillon
Soit une population de moyenne μ connue et d'une
variance σ2 connue.
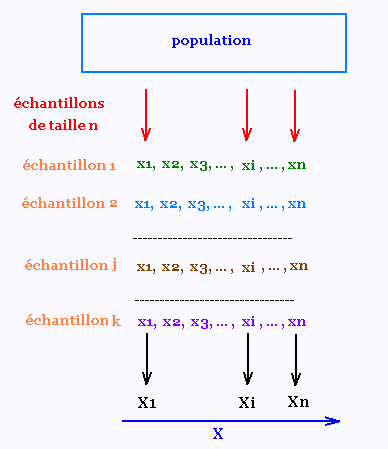
De cette populatio, on prélève au hasard des échantillons de taille n.
L'échantillon j contient n éléments et est de la forme {x1, x2, ..., xi, ..., xn}.
À chaque colonne {xi}, on lui associe une variable aléatoire
Xi de moyenne μ et de variance σ2 qui sont
les paramètres relatifs à la population. C'est à dire:
E(Xi) = μ et V(Xi) = σ2
Maintenant, on s'interesse au calcul de la moyenne des
xi pour chaque échantillon. Cette moyenne diffère d'un
échatillon à l'autre. Certains peuvent être constitués d'éléments
atypiques et avoir une moyenne très différente de celle de la population,
surtout si l'échantillon est de petite taille.
Soit X la variable aléatoire qui, à chaque échantillon j
de taille n, associe la moyenne des xi.
La moyenne des n valeurs de l'échantillon est :
= (X1 + X2 + ... + Xi + ... + Xn)/n
Les variables aléatoires Xi suivent la loi normale N(μ, σ)
.
D'après les propriétés de la loi normale, une combinaison linéraire de variables aléatoire qui suivent la loi normale est une variable aléatoire qui suit la loi normale.
Comme chaque variable aléatoire Xi suit la loi normale N(μ, σ), la variable aléatoire moyenne X suit donc également une loi
normale de paramètres E(X) et V(X) que nous allons calculer.
D'après la propriété de linéarité de l'espérance :
Si X est une variable aléatoire qui suit une loi normale N(μ,σ)
sur une population,
On prélève avec remise, au hasard, un échantillon de taille n de
moyenne ,
alors la variable aléatoire suit également une loi
normale N(μ,σ/√n)
Pour des échantillons de grande taille (≥ 30):
Théorème Central Limite - Version 2:
Si X est une variable aléatoire qui suit une loi quelconque sur la population d'espérance E(X) = μ et de variance V(X) = σ2,
On prélève avec remise, au hasard, un échantillon de taille n, avec n ≥ 30, de moyenne ,
alors la variable aléatoire X suit approximativement une loi normale:
N(μ,σ/√n)
Les paramètres de l'échantillon prélevé n'interviennent
pas dans ces calculs.
Exemple
Les statistiques faites sur une population d'oranges
qui en compte une centaine sont connues. La masse moyenne
d'une orange μ = 199.5 g, son écart-type σ = 2.06 g.
On prélève un échatillon de 49 oranges. On veut savoir la probabilité
que la moyenne des masses de cet échantillon soit supérieure à 200 g.
À partir des paramètres connus μ et σ de la population,
on calcule ceux de l'échantillon.
La taille de l'échantillon = 45 est ≥ 30. Nous ne connaissons pas
la loi sur la population. Ainsi la variable aléatoire
X sur la population, suit ou non une loi normale importe peu. On applique
le théorème de la limite centrale - version 2.
On note la variable aléatoire qui, à tout échantillon de taille n = 49, fait correspondre sa moyenne.
On conclue que la variable aléatoire suit approximativement une loi normale:
N(μ,σ/√n) = N(199.5,2.06 /√49) = N(199.5,0.29)
La distribution normale centrée et réduite Z de la distribution
normale est Z = ( - μ)/(σ/√n). C'est à dire que Z suit N(0,1).
On a donc P( > 200) =
P(Z > (200 - 199.5)/0.29) = P(Z > 1.724)
La loi normale (gaussiènne) centrée et réduite donne,
par lecture sur table ou utilisation du logiciel, P(Z > 1.724) = 0.0424
Conclusion : il y a environ 4% de chance que, dans cet échantillon
d'oranges, la moyenne des masses soit supérieure à 200 g.
2. Proportion dans un échantillon
Nous avons une population sur laquelle on veut étudier
un caractère (ou attribut) A dont on connaît la
proportion p dans la population.
On prélève des échantillons de taille n.
La proportion du caractère A dans chaque échantillon n,est
pas la même. Elle dépend de l'échantillon choisi.
Notons F la variable aléatoire qui, à chaque échantillon j
de taille n, associe sa proportion pj du caractère A .
La variable aléatoire F est appellé distribution des
fréquence des échantillons.
Nous allons avoir ici un modèle binomial ou apparenté dont on sait qu'il converge vers la loi normale.
Pour tout élement xi d'un échatillon, compris entre 1 et
n, on note Xi la variable aléatoire définie par :
Xi = 1 si xi possède le caractère A,
Xi = 0 sinon.
La variable aléatoire Xi suit une loi de Bernoulli de paramètre p.
C'est un modèle binomial qui converge vers la loi normale.
Maintenant, en plus de la fonction aléatoire F,
on considère une variable aléatoire X somme de tous
les Xi de d'un échantillon:
X = X1 + X2 + X3 + ... + Xn.
La variable aléatoire X est binomiale de paramètres n et p.
X suit B(n,p)
Ainsi E(X) = np et σ(X) = √[np(1 - p)]
On remarque que la variable aléatoire F = X/n
correpond ainsi à la fréquence de l'attribut A
dans l'échantillon.
D'après les propriétés de l'espérance et de l'écart-type, on
a:
On considère une population sur laquelle on étudie un caractère A
répandu avec une fréquence p:
On prélève avec remise, au hasard, un échantillon de grande
taille n avec n ≥ 30,
On note F la fréquence du caractère A dans l'échantillon,
Alors la variable aléatoire F suit approximativement une loi normale :
F suit N(p, √[p(1 - p)/n])
Exemple
Dans une population d'oranges, on sait que 65%
des ces oranges sont mures.
On prélève un échantillon de 40 oranges.
On veut savoir la probabilité que, dans l'échantillon,
entre 60 % et 70 % des oranges sont mures?
Nous avons n = 40 et p = 0,65. La variable aléatoire F
correspondant à la fréquence de murissement des oranges.
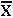 des n valeurs de l'échantillon est :
des n valeurs de l'échantillon est :
 Les statistiques faites sur une population d'oranges
qui en compte une centaine sont connues. La masse moyenne
d'une orange μ = 199.5 g, son écart-type σ = 2.06 g.
Les statistiques faites sur une population d'oranges
qui en compte une centaine sont connues. La masse moyenne
d'une orange μ = 199.5 g, son écart-type σ = 2.06 g.

