Statistiques
Statistiques
descriptives
Échantillonage
Éstimation
Statistiques
inférentielles
Statistiques
Calculateurs
© The scientific sentence. 2010
|
Mathématiques 2: Statistiques :
Éstimation
ponctuelle et par intervalle
n N V(χ̄) V(χ) V(χi) μ σ σe S2 ƒ p
χ χi m
x̄
X̄
χ̄
σ̂
μ̂
μX̄
σ2X̄
1. Définitions
Le but de l'estimation en statistques est, à partir des
paramètres comme la moyenne, la variance, ou la proportion calculés sur un échantillon, d'estimer ceux d'une population entière.
L'estimation est la réciproque de l'échantillonnage. On utilise les résultats
établis sur la théorie de l'échantillonnage, c'est à dire, de la distribution d’échantillonnage, pour estimer ceux de la population parente.
Il s'agit bien d'utiliser des observations faites sur un échantillon
et de tirer des conclusions sur la population toute entière. C'est approche qui n'est pas déductive, qui va du général au particulier, mais plutôt
d'une démarhe statistique inductive ou inferentielle.
En théorie de l’estimation, on distingue les concepts suivants:
• les paramètres de la population comme la moyenne μ ou la variance
σ2 dont les valeurs sont certaines mais inconnues.
• les résultats de l’échantillonnage comme la moyenne m ou la variance
s2 dont les valeurs sont certaines et connues.
• les variables aléatoires des paramètres, comme la moyenne aléatoire
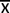 dont la valeur est incertaine et
dont la loi de probabilité est souvent connue.
dont la valeur est incertaine et
dont la loi de probabilité est souvent connue.
Nous étudierons deux cas : celui où estime la moyenne μ d'une variable aléatoire définie sur une population et celui où l'on estime la proportion d'individus p ayant un certain caractère dans la population.
Pour estimer les paramètres de la loi de probabilité, la méthode utilisée
est dite méthode du maximum de vraisemblance lorsque
la distribution de la variable aléatoire X est connue.
Si la distribution n'est pas connue, on utilise
la méthode des moindres carrés.

2. Estimation ponctuelle
2.1. Définition
L’estimation d’un paramètre quelconque est ponctuelle si elle ne prend qu'une seule valeur.
L'estimation d'un paramètre, c'est sa valeur estimée. Elle est appelée estimateur du paramètre.
On estime un paramètre inconnu d'une population à partir des données observables sur un échantillon aléatoire.
On note θ̂
l'estimateur du paramètre θ .
L’estimation par intervalle associe à un échantillon aléatoire, un intervalle [θ̂1,θ̂2] qui recouvre θ avec une certaine probabilité.
2.2. Estimateur des deux paramètres μ
et σ2 d'une loi normal N(μ,σ2)
On considère une loi normale N(μ, σ) sur une population dont la valeur des paramètres μ n’est pas connue pour laquelle on souhaite estimer l’espérance μ.
Soient X une variable aléatoire continue suivant cette loi normale et
X1 , X2 ,…, Xi , ..., Xn , n réalisations indépendantes de la variable
aléatoire X.
Un estimateur du paramètre θ est une variable aléatoire θ̂
fonction des Xi.
L'estimateur θ̂
du paramètre θ obéit aux deux relations suivantes:
E (θ̂) = θ et
V(θ̂) est minimale.
On notera :
μ̂
l'estimateur de μ et
σ2̂
l'estimateur de σ2.
On cherche
μ̂ et
σ2̂
de telle sorte que:
E (μ̂ ) = μ et
V(μ̂ ) soit minimale ; puis
E (σ2̂) = σ2 et
V(σ2̂) soit minimale.
2.2.1. Espérance
Un estimateur du paramètre μ est une variable aléatoire μ̂ fonction des Xi.
On utilse la méthode des moindres carrés qui consiste à rechercher les coefficients de la combinaison linéaire
μ̂ = c1 X1 + c2 X2 +... + ci Xi + ... + cn Xn
telle que
E (μ̂ ) = μ et
V(μ̂ ) soit minimale.
Nous avons X̄ = ΣXi/n.
Donc
E(X̄) = μ
μ, est l'espérance de la loi de probabilité de la variable aléatoire X.
Ainsi
μ̂ = X̄ = ΣXi/n,
La moyenne arithmétique constitue le meilleur estimateur de μ.
μ̂ = X̄ = ΣXi/n.
2.2.2. Variance
Soit X une variable aléatoire continue suivant une loi normale N (μ,Σ) pour laquelle on souhaite estimer la variance Σ2.
Soient X1 , X2 ,…, Xi , ..., Xn , n réalisations indépendantes de la variable aléatoire X.
Un estimateur σ2̂ du paramètre σ2 est une fonction des variables aléatoires Xi :
σ2̂ = f (X1 , X2 ,…, Xi , ..., Xn)
Nous avons deux cas:
1. Cas où l’espérance μ est connue
On utilse la méthode des moindres carrés qui consiste à rechercher les coefficients de la combinaison linéaire
σ2̂ = c1(X1 - μ)2 + c2(X2 - μ)2 + ... + ci(Xi - μ)2 + ... + cn ( Xn - μ)2
telle que
E (σ2̂) = σ2 et
V(σ2̂) soit minimale.
La variance de la loi de probabilité de la variable aléatoire X
est la variance observée. C'est le meilleur estimateur de σ2 lorsque μ est connue:
σ2̂ = (1/n)Σ(Xi - μ)2.
2. Cas où l’espérance μ est inconnue
On estime μ à μ̂ =
X̄ et on calcule la variance
observée S2:
S2 = (1/n) Σ (Xi - X̄)2 =
(1/n) Σ (Xi - μ + μ - X̄)2
= (1/n) Σ (Xi - μ - (X̄) - μ)2
= (1/n) Σ (Xi - μ)2 - 2 X̄ -μ)(1/n) Σ(Xi - μ)
+ (X̄ - μ)2 =
(1/n) Σ (Xi - μ)2 - 2 (X̄ - μ) 2
+ (X̄ - μ)2
=
(1/n) Σ (Xi - μ)2 - (X̄ - μ)2
(1/n) Σ (Xi - μ)2 est la variance de la population
= σ2. Ainsi
(X̄ - μ)2 =
(Σ Xi/n - (1/n) n μ)2 =
(1/n2)(Σ Xi - Σμ)2 =
(1/n) (1/n)(Σ Xi - Σμ)2 = (1/n) σ2
Ainsi
S2 = σ2 - (1/n) σ2 =
[(n - 1)/n]σ2
Finalement,
S2 = σ2 - (1/n) σ2 =
σ2 = [n/(n - 1)] S2
Le meilleur estimateur de σ2 σ2̂, variance de la loi de probabilité de la variable aléatoire
X associée à la population lorsque l’espérance μ est inconnue est :
σ2̂ = [n/(n - 1)]S2
=
[1/(n - 1)]Σ(Xi - X̄)2
On remarque que lorsque n tend vers l'infini n/(n - 1) tend vers 1,
et donc σ2̂ = S2.
La variance observée S2 tend vers la variance de la population
σ2.
On considère une variable aléatoire X sur une population de moyenne (ou espérance) μ inconnue et d'écart-type σ inconnu ou connu.
On prélève avec remise un échantillon de taille n sur lequel on a
calculé la moyenne μe et l'écart-type σe.
Une estimation ponctuelle
μ̂
de la moyenne μ de la population est :
μ̂
= μe
Une estimation ponctuelle
σ̂
de
l'écart-type σe de la population est :
σ̂
= √[n/(n - 1)] σe
2.2.3. Fréquence
On considère une population dont certains individus ont
un certain caractère A. On note p la fréquence des individus de la population possédant le caractère A. La valeur de ce paramètre p étant inconnu, on cherche à l'estimer à partir des données observables sur un échantillon.
Ce problème est équivalent est régit par la loi de Bernoulli
dans lequel le caractère A correspond au succès.
A chaque échantillon non exhaustif de taille n, on associe l’entier k, nombre d’individus possédant le caractère A.
Soit K une variable aléatoire discrète suivant une loi binomiale B(n,p) et pour laquelle on souhaite estimer la fréquence p.
La fréquence observée du nombre de succès observé de trouver
le caractère A dans un échantillon de taille n
constitue le meilleur estimateur de p:
p̂ = K/p
2. Estimation par intervalle
2.1. Définition
L’estimation par intervalle associe à un échantillon aléatoire, un intervalle [θ̂1,θ̂2] qui recouvre θ avec une certaine probabilité.
Cet intervalle dans lequel on estime un paramètre θ est appelé l’intervalle de confiance du paramètre θ .
La probabilité que le paramètre
θ dont la valeur est inconnue se trouve compris entre les estimateurs θ̂1 et θ̂2 est égale définie par 1 - α.
Le coéfficient 1 - α est appelé coefficient de confiance.
P(θ̂1 < θ < θ̂2) = 1 - α
Son complément α est appelé coefficient de risque.
P(θ ∉ [θ̂1, θ̂2] = α
Un intervalle de confiance indique la précision d’une estimation.
Pour un risque α donné, l’intervalle de
confiance est d’autant plus grand que la précision est faible
Dans la représentation graphique d'une distribution
ou de fonction de répartition, les deux aires aux extrêmes de la courbe représente le coefficient de risque aα. Ainsi de part et d’autre de la distribution, la valeur d'une aire α/2.
Généralement, on prend α = 0.01, 0.05 ou
0.01 pur un coefficient de risque. Le plus courant est α = 0.05.
Par exemple, pour α = 0,05, nous avons
95 de chances sur 100 que la valeur du paramètre recherché se trouve dans l’intervalle de confiance et donc la précision autour de la valeur prédite est correcte. La
precision sera faible avec α = 0.01,
mais élevée avec 0.10.

2.2. Intervalle de confiance d’une moyenne
La nature de la variable aléatoire continue X, la taille de l’échantillon n et de la valeur du paramètre σ2, déterminent l’intervalle de confiance autour de μ.
1. cas ou X tend vers une la loi N(μ,σ), n est quelconque, σ2 est connue
On veut donc établir l’intervalle de confiance autour de la moyenne μ.
Celà revient à établir la valeur d'un nombre c tel que, pour une valeur du coéfficient de confiance 1 - α donnée, on aura:
P(X̄ - c < μ < X̄ + c) = 1 - α
C'est à dire
P(- c < X̄ - μ < c) = 1 - α
ou
P(- c/(σ/√n) < (X̄ - μ)/(σ/√n) < + c/(σ/√n)) =
1 - α
Avec (X̄ - μ)/(σ/√n) → N(0,1)
Ainsi |c/(σ/√n))| correspond à la valeur
de la variable normale réduite pour la probabilité α donnée.
Cette valeur de |c/(σ/√n))| est appelée
écart réduit et est noté εα
L'expression de la valeur de c réduit est donc:
c = εα σ/√n
L’intervalle de confiance de la moyenne μ pour un coefficient de risque α est donc
X̄ - εασ/√n < μ < X̄ + εα σ/√n
X tend vers une la loi N(μ,σ), n etant quelconque, σ2 est connue.
La valeur de εα est donnée par la table de l’écart-réduit pour une valeur α donnée.
Coefficient
de risque α |
Ecart-réduit εα |
| 0,01 | 2,576 |
| 0,05 | 1,960 |
| 0,10 | 1,645 |
2. cas ou X tend vers la loi N(μ,σ), n est quelconque, σ2 est inconnue
Comme pour l'estimation ponctuelle on estime la variance de la population à
σ̂2
= [n/(n - 1)]S2.
S2 est la variance de l'échantillon.
On estime donc la moyenne X̄ comme suit:
P(- c/(σ̂ /√n) < (X̄ - μ)/(σ̂ /√n) < + c/(σ̂/√n)) =
1 - α
Avec (X̄ - μ)/(σ̂/√n) → T(ddl = n - 1)
T(ddl = n - 1) est la loi de Student pour un ddl = n - 1.
Ainsi |c/(σ̂/√n))| correspond à la valeur tα
de la variable de Student pour un ddl = n - 1, et pour la probabilité α donnée.
Nous avons donc
tα = |c/(σ̂/√n)|, ou
c = tα σ̂/√n
L’intervalle de confiance de la moyenne μ pour un coefficient de risque α est donc
X̄ - tασ̂√n < μ < X̄ + tα σ̂/√n
X tend vers une la loi T(n - 1, α) de Student, n étant quelconque, σ2 est inconnue.
Lorsque n < 30, la loi de student converge
vers une loi normale réduite. Ainsi La valeur de
tα(n-1) est égale à celle de
l'écart réduit εα
Exemple pour un risque
α = 0,05
Taille de
l’échantillon n | Ecart-réduit εα | Variable DE student tα |
| 10 | 1.960 | 2.228
|
| 20 | 1.960 | 2.086
|
| 30 | 1.960 | 2.042
|
| 40 | 1.960 | 1.960
|
3. cas ou X suit une loi inconnu et n > 30
Puisque par définition la variance de la population est inconnue, elle doit donc être estimée avec la variance observée comme pour le cas précédent:
σ2̂ = [n/(n - 1)]S2
la loi suivie par la variable centrée réduite
(X̄ - μ)/(σ̂/√n) → N(0,1)
L’intervalle de confiance de la moyenne μ pour un coefficient de risque α est donc
X̄ - εασ̂√n < μ < X̄ + εα σ̂/√n
n étant grand (> 30).
4. cas ou X suit une loi inconnuE et n < 30
La loi de probabilité suivie par (X̄ - μ)/(σ̂/√n)
n’est pas connue. Dans ce cas, on a recours aux statistiques non paramétriques.
2.3. Intervalle de confiance d’une proportion
L’intervalle de confiance autour de la fréquence p de la population à partir de son estimateur K/n correspond à la valeur de c pour une valeur du coefficient de confiance (1 - α) telle que :
P(K/n - c < p < K/n + c ) = 1 - α
ou
P(p - c < K/n < p + c ) = 1 - α
On a aussi
P( - c < K/n - p < c ) = 1 - α
P( - c/√(p(1 - p)/n) < (K/n - p)/√(p(1 - p)/n) < c/√(p(1 - p)/n)) = 1 - α
Avec (K/n - p)/√(p(1 - p)/n) → N(0,1)
La valeur |c/√(p(1 - p)/n)| est la valeur de la variable normale réduite pour la probabilité α donnée appelée aussi écart réduit et notée εα.
On estime la variance V(K/p) = pq qui est inconnue
par p̂q̂/n
avec
q = 1 - p
p̂ = K/n, et q̂ = (n - K)/n
L’intervalle de confiance de la fréquence p pour un coefficient de risque α est donc
K/n - εα√[p̂q̂/n] < p < K/n + εα √[p̂q̂/n]
n étant grand (> 30) et np, nq ≥5.
|
|